Understanding Tree Algorithms — Advanced Optimization
Memory layout, CPU cache considerations, performance benchmarks, and real-world applications in production systems.
Memory layout, CPU cache considerations, performance benchmarks, and real-world applications in production systems.
Author
Mr. Oz
Date
Read
12 mins
Level 3
Author
Mr. Oz
Date
Read
12 mins
Share
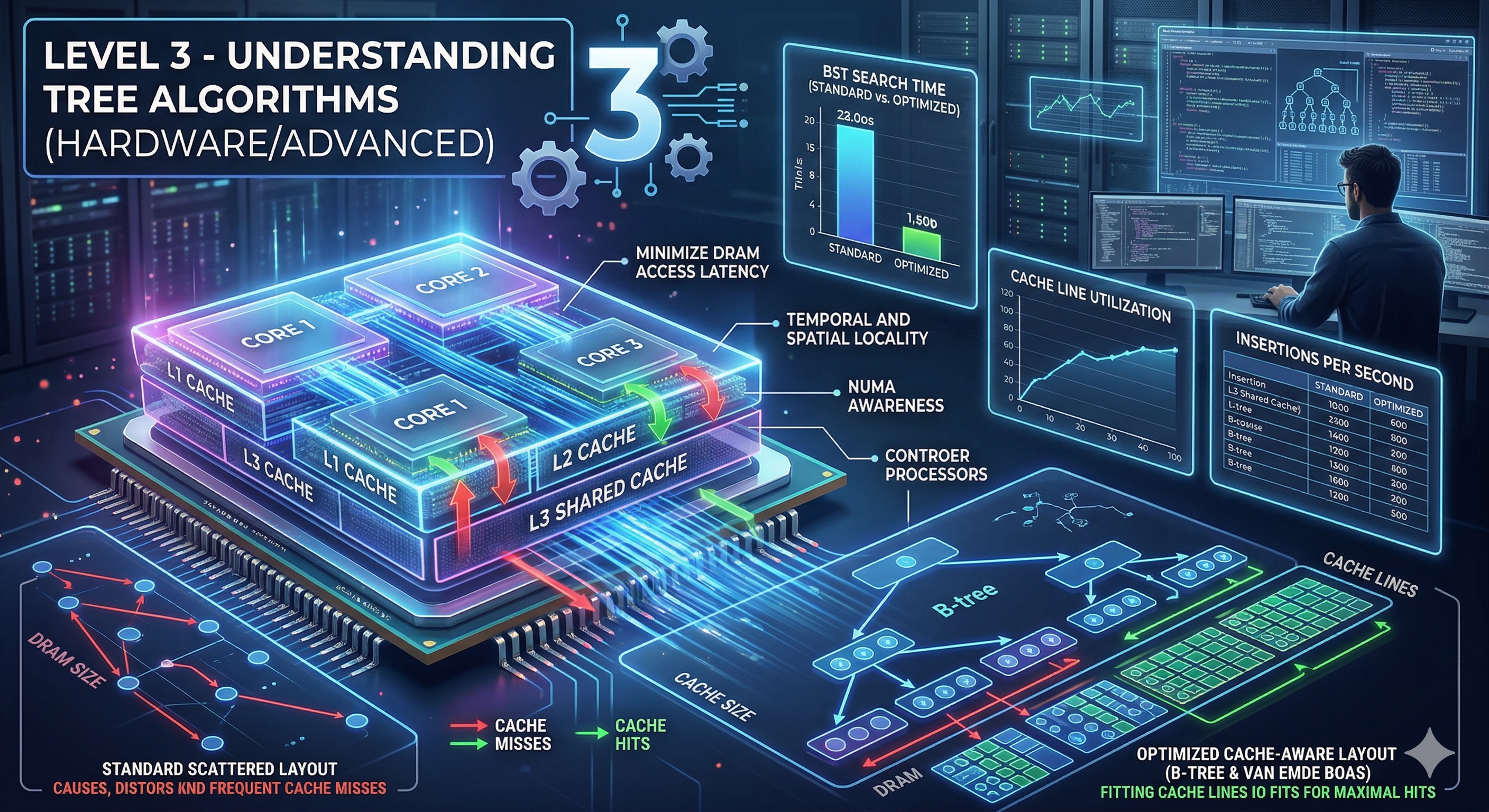
Now we go beyond the algorithm to understand how tree operations perform at the hardware level. Memory layout, cache behavior, and data structure choices can dramatically impact real-world performance.
Traditional pointer-based trees have a hidden performance cost: cache misses.
Benchmark: Array-based tree traversal can be 2-10x faster than pointer-based for the same logical tree!
Modern CPUs have multiple cache levels (L1, L2, L3). Understanding this hierarchy is crucial for tree algorithm optimization:
Key insight: A single cache miss to RAM costs as much as 100-300 L1 cache hits!
Store tree in array where node i's children are at 2i+1 and 2i+2. Excellent for complete binary trees.
Allocate nodes level-by-level instead of depth-first to improve spatial locality.
Prefetch likely-to-be-accessed child nodes before processing current node.
Add pointers to successor/predecessor nodes to avoid stack/recursion overhead.
The Linux kernel uses red-black trees for scheduling, memory management, and filesystem operations. They chose RB-trees for their guaranteed O(log n) operations and memory efficiency.
Database indexes use B+ trees optimized for disk I/O. The wide nodes reduce tree height and maximize cache line utilization.
Git uses Merkle trees (content-addressed) for commits. Finding common ancestors (merge-base) is essentially an LCA problem!
Routing protocols use tree structures for finding paths. LCA algorithms help determine optimal routing paths and detect network topology.
Sometimes trees aren't the best choice: