Understanding Tree Algorithms — Implementation Deep Dive
Recursive vs iterative approaches, stack-based implementations, and production-ready code for finding the Lowest Common Ancestor.
Recursive vs iterative approaches, stack-based implementations, and production-ready code for finding the Lowest Common Ancestor.
Author
Mr. Oz
Date
Read
8 mins
Level 2
Author
Mr. Oz
Date
Read
8 mins
Share
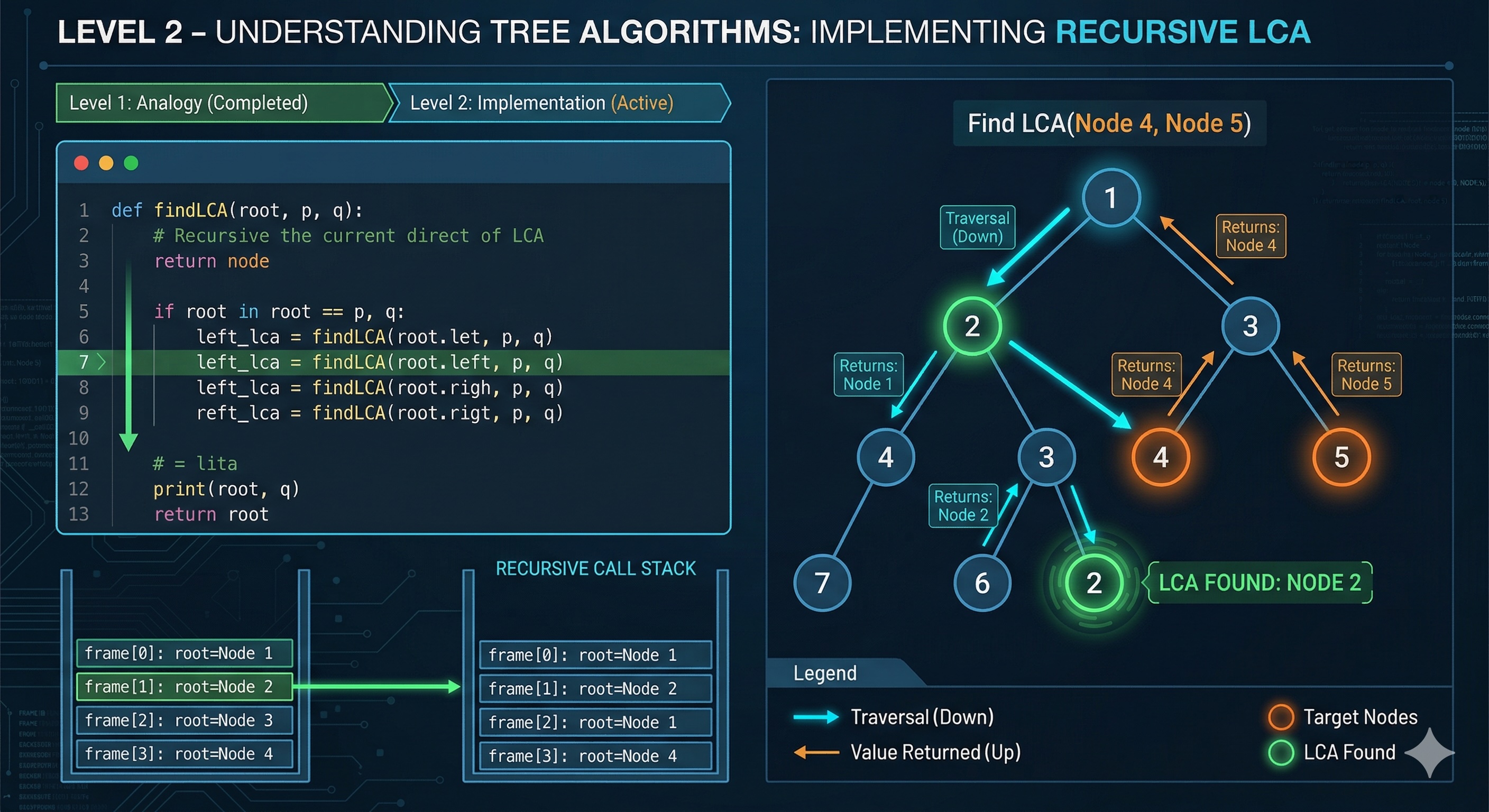
Now that we understand the family gathering analogy, let's dive into the actual implementation. We'll explore recursive solutions, iterative approaches, and production-ready patterns.
First, let's define a binary tree node. A node contains three things:
# Python implementation
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left # Left child
self.right = right # Right child
// Java implementation
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int val) { this.val = val; }
}
// C++ implementation
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};The recursive approach follows these steps:
def lowestCommonAncestor(root, p, q):
# Base case: found target or reached end
if not root or root == p or root == q:
return root
# Search both subtrees
left = lowestCommonAncestor(root.left, p, q)
right = lowestCommonAncestor(root.right, p, q)
# If both found, current is LCA
if left and right:
return root
# Propagate the found node upward
return left if left else rightThe algorithm exploits a key insight: the first node where p and q are found in different subtrees IS the LCA.
Both null
Neither p nor q in this subtree → return null
One non-null
Found p OR q in this subtree → propagate up
Both non-null
p and q in different branches → THIS is LCA!
In the worst case, we visit every node once. The algorithm terminates early if both targets are found in the same subtree.
The recursion stack uses space proportional to tree height h. O(n) for skewed trees, O(log n) for balanced trees.
== for reference comparison.