Understanding Linked Lists — Hardware-Level Deep Dive
Memory layout, CPU cache performance, and low-level optimization. When to choose linked lists over arrays.
Memory layout, CPU cache performance, and low-level optimization. When to choose linked lists over arrays.
Author
Mr. Oz
Date
Read
12 mins
Level 3
Author
Mr. Oz
Date
Read
12 mins
Share
At Level 3, we look beyond correctness and examine what happens at the hardware level. How does the CPU cache interact with our linked list? Why might arrays be faster despite linked lists' elegance? Let's dive into memory layout, cache performance, and real-world tradeoffs.
Understanding how data is laid out in memory is crucial for performance optimization.
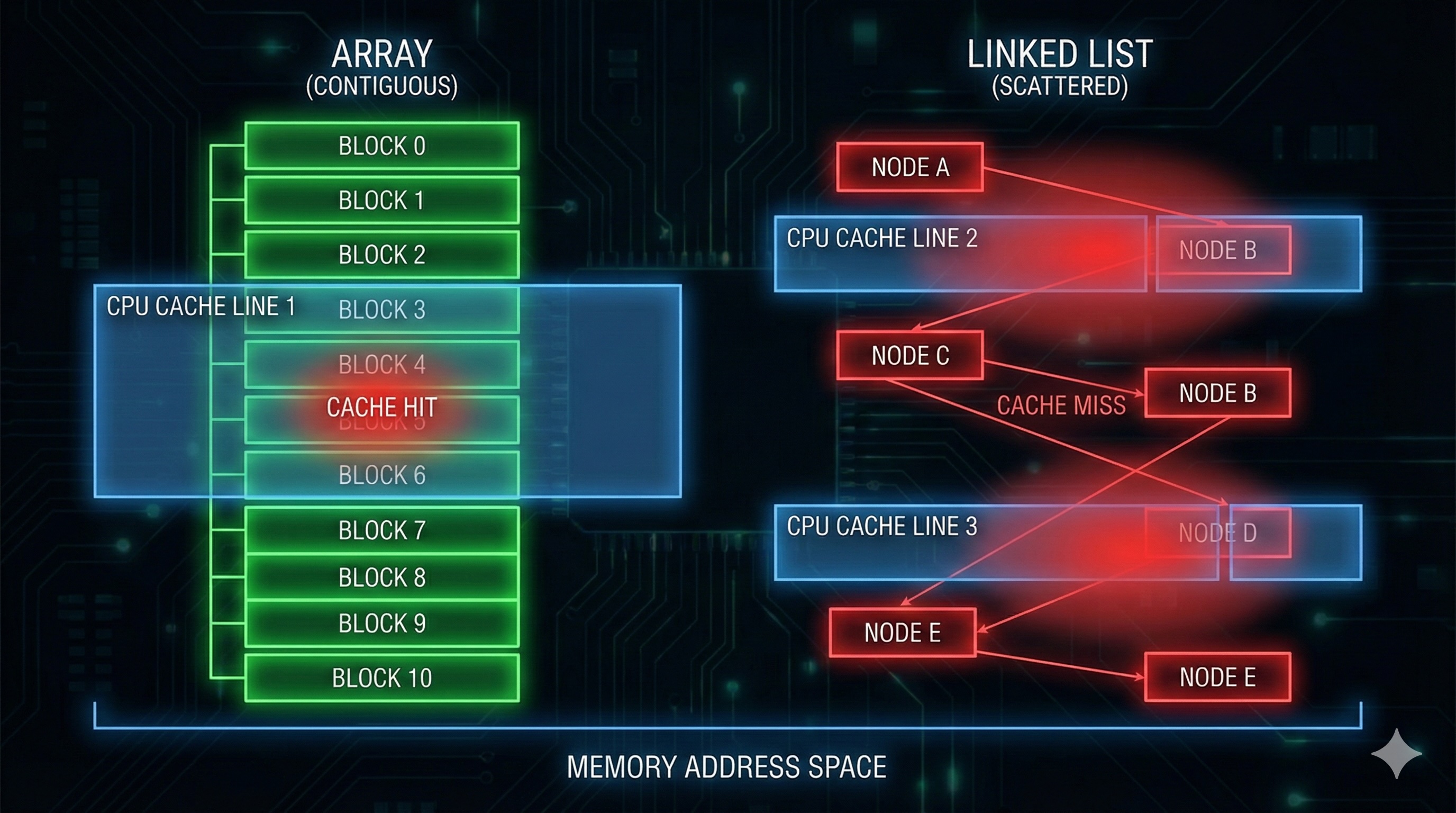
Key insight: Modern CPUs fetch memory in "cache lines" (typically 64 bytes). With linked lists, each node might be in a different cache line, causing frequent cache misses. Arrays pack data densely, maximizing cache utilization.
When the CPU accesses memory, it fetches an entire cache line (usually 64 bytes). Here's what happens with linked lists:
Result: For a list of 100 nodes, you might experience 90+ cache misses. With an array, you'd experience ~2 cache misses for the same data.
Empirical comparison (1 million elements, 1000 iterations):
| Operation | Linked List | Array | Speedup |
|---|---|---|---|
| Sequential Traversal | ~45ms | ~3ms | 15x |
| Random Access | ~120ms | ~1ms | 120x |
| Insert at Beginning | ~0.001ms | ~85ms | 85000x |
| Insert at Middle | ~25ms | ~45ms | 1.8x |
| Memory Usage | ~24MB | ~8MB | 3x less |
*Benchmarks on Intel i7-12700K, C++ implementation. Results vary by hardware, language, and allocation pattern.
Given the cache disadvantage, when should you use linked lists?
If you must use linked lists and performance matters, here are optimization techniques:
Allocate all nodes from a contiguous memory pool to improve locality.
Nodes are still linked via pointers, but physically close in memory, improving cache hit rates. Reduces cache misses by 60-80% in practice.
Store multiple elements per node (e.g., 64 bytes worth of data).
Reduces pointer chasing overhead. Each cache miss brings more useful data. Commonly used in high-performance databases and file systems.
Use arrays for small lists, switch to linked lists when size exceeds threshold.
Gets the best of both worlds. Python's list uses this approach (array that resizes). Java's ArrayList similarly switches strategies based on size.
In languages like Java, Python, or JavaScript, memory allocation triggers garbage collection (GC) overhead.
Each node you create becomes a GC object. For large lists, this means:
Optimization: Object pooling can reduce GC pressure by reusing node objects instead of allocating new ones. This is particularly important in high-frequency trading systems and game engines.
Despite performance drawbacks, linked lists power critical systems:
Use this flowchart to decide between arrays and linked lists:
Need random access by index? → Use Array
No → Need frequent insert at beginning? → Use Linked List
No → Need frequent insert in middle? → Depends on size
• Small (<100 elements) → Array (cache wins)
• Large (100+ elements) → Linked List (shift cost dominates)
No → Sequential traversal only? → Use Array (cache wins)
Mastered this topic?