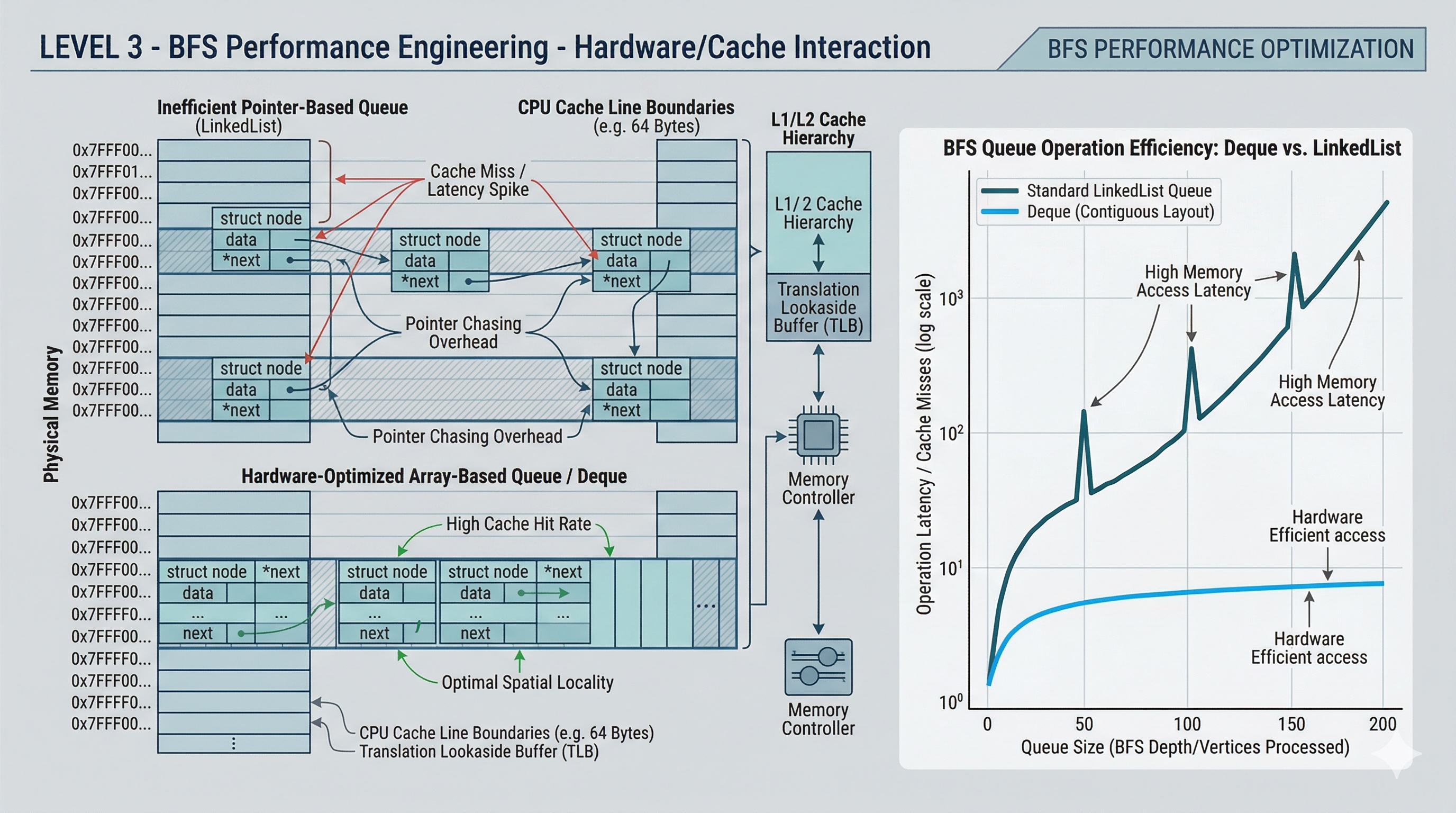
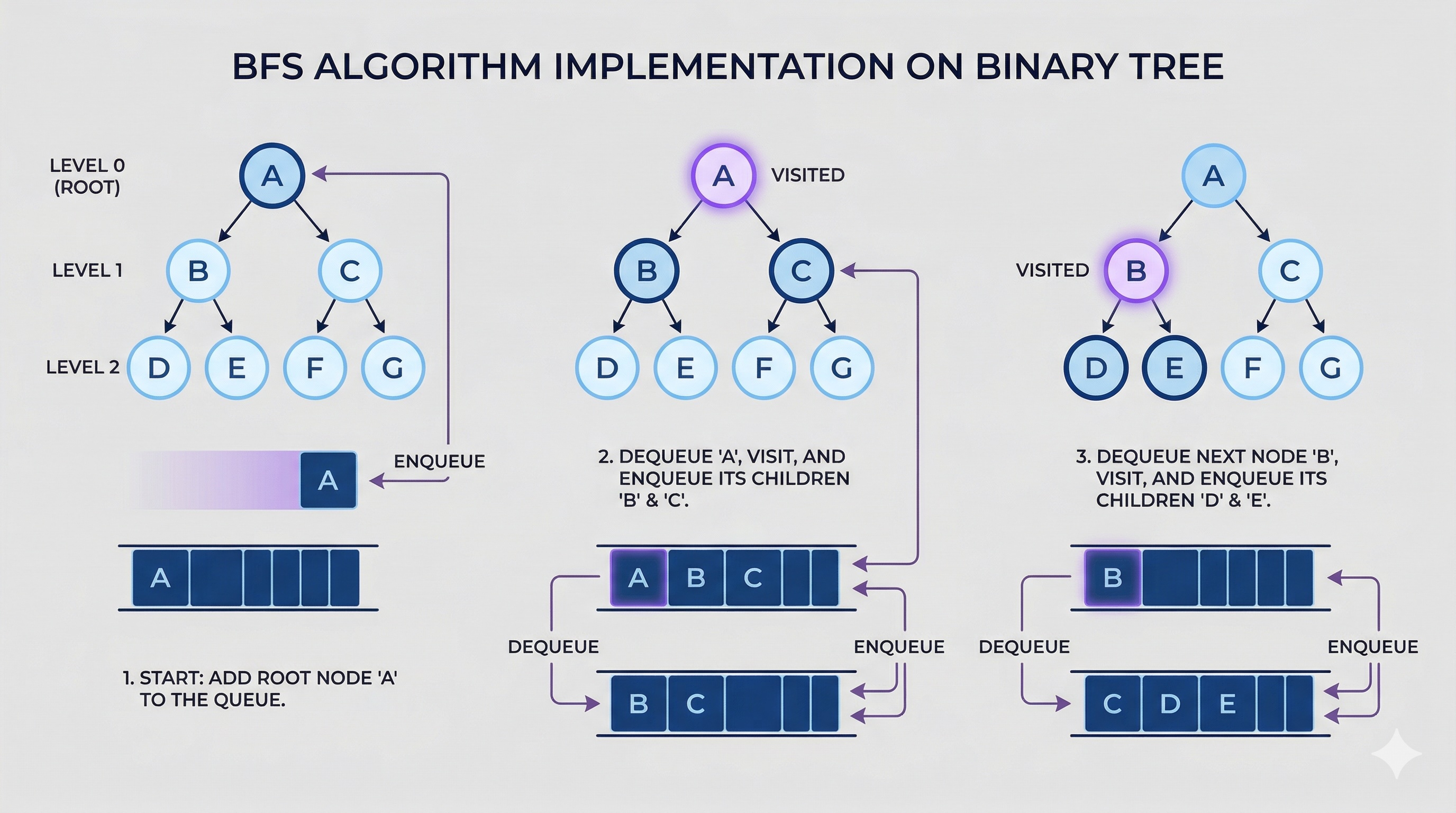
0-1 BFS (Deque-Based Weighted BFS)
For graphs with edge weights of only 0 or 1, use a deque instead of a priority queue. Push weight-0 edges to the front, weight-1 edges to the back. Runs in O(V+E) instead of Dijkstra's O((V+E) log V).
def bfs_01(graph, start, n):
dist = [float('inf')] * n
dist[start] = 0
dq = deque([start])
while dq:
u = dq.popleft()
for v, w in graph[u]: # w is 0 or 1
if dist[u] + w < dist[v]:
dist[v] = dist[u] + w
if w == 0:
dq.appendleft(v) # Front for weight 0
else:
dq.append(v) # Back for weight 1
return dist
Multi-Source BFS
Start BFS from multiple sources simultaneously. Classic example: the "rotten oranges" problem. Initialize the queue with all source nodes at distance 0, then BFS as usual.
def multi_source_bfs(grid, sources):
queue = deque()
visited = set()
for r, c in sources:
queue.append((r, c, 0)) # All sources start at distance 0
visited.add((r, c))
while queue:
r, c, dist = queue.popleft()
for dr, dc in [(0,1),(0,-1),(1,0),(-1,0)]:
nr, nc = r+dr, c+dc
if 0 <= nr < len(grid) and 0 <= nc < len(grid[0]):
if (nr, nc) not in visited:
visited.add((nr, nc))
queue.append((nr, nc, dist+1))
Bidirectional BFS
Run BFS from both the source and target simultaneously. When the two frontiers meet, you have the shortest path. Reduces time complexity from O(bd) to O(bd/2) where b is the branching factor and d is the distance.
def bidirectional_bfs(graph, start, end):
if start == end: return 0
front_a, front_b = {start}, {end}
visited_a, visited_b = {start}, {end}
depth = 0
while front_a and front_b:
depth += 1
# Always expand the smaller frontier
if len(front_a) > len(front_b):
front_a, front_b = front_b, front_a
visited_a, visited_b = visited_b, visited_a
next_front = set()
for node in front_a:
for neighbor in graph[node]:
if neighbor in visited_b:
return depth # Frontiers met!
if neighbor not in visited_a:
visited_a.add(neighbor)
next_front.add(neighbor)
front_a = next_front
return -1 # No path
Impact: For a graph with branching factor 10 and distance 6: standard BFS explores ~106 = 1,000,000 nodes. Bidirectional BFS explores ~2 x 103 = 2,000 nodes. A 500x improvement.
A* as an Informed BFS Variant
A* extends BFS with a heuristic function h(n) that estimates the remaining cost to the goal. It explores nodes in order of f(n) = g(n) + h(n), where g(n) is the known cost from the start. With an admissible heuristic, A* is optimal and often explores far fewer nodes than plain BFS.