The BFS Template
Every BFS implementation follows the same universal pattern. Memorize this template and you can apply it to any BFS problem:
The Universal BFS Pattern
- Initialize a queue with the starting node(s)
- While the queue is not empty:
- Dequeue a node from the front
- Process the current node
- Enqueue all unvisited neighbors
- Repeat until queue is empty
This pattern guarantees that nodes are visited in order of their distance from the starting node, which is why BFS naturally finds the shortest path in unweighted graphs.
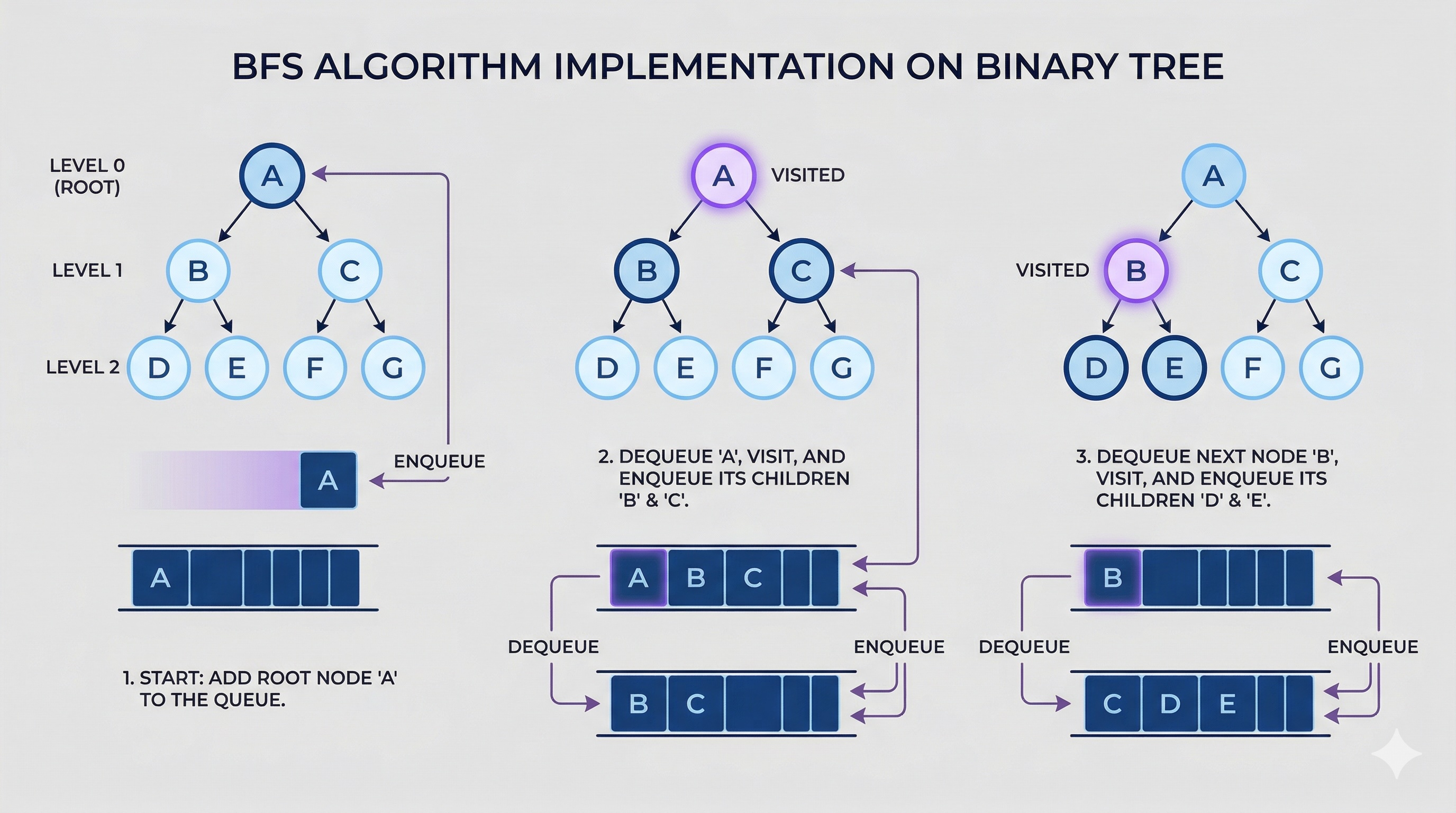
BFS on Binary Trees
Level order traversal is the classic BFS application on trees. We visit all nodes at depth d before any node at depth d+1.
Python
from collections import deque
def level_order_traversal(root):
"""Perform BFS level order traversal on a binary tree."""
if not root:
return []
result = [] # Stores the final level-by-level result
queue = deque([root]) # Initialize queue with root node
while queue:
level_size = len(queue) # Number of nodes at current level
current_level = [] # Stores nodes for this level
for _ in range(level_size):
node = queue.popleft() # Dequeue from front (FIFO)
current_level.append(node.val)
# Enqueue children for next level
if node.left:
queue.append(node.left) # Add left child to back of queue
if node.right:
queue.append(node.right) # Add right child to back of queue
result.append(current_level) # Add completed level to result
return result # e.g., [[1], [2, 3], [4, 5, 6, 7]]
Java
import java.util.*;
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if (root == null) return result;
// LinkedList implements Queue interface — use it for BFS
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root); // Enqueue the root node
while (!queue.isEmpty()) {
int levelSize = queue.size(); // Snapshot current level size
List<Integer> currentLevel = new ArrayList<>();
for (int i = 0; i < levelSize; i++) {
TreeNode node = queue.poll(); // Dequeue from front (FIFO)
currentLevel.add(node.val);
// Enqueue children for the next level
if (node.left != null) queue.offer(node.left);
if (node.right != null) queue.offer(node.right);
}
result.add(currentLevel); // Add completed level to result
}
return result;
}
C++
#include <queue>
#include <vector>
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> result;
if (!root) return result;
queue<TreeNode*> q; // STL queue for BFS
q.push(root); // Enqueue root node
while (!q.empty()) {
int levelSize = q.size(); // Nodes at current level
vector<int> currentLevel;
for (int i = 0; i < levelSize; i++) {
TreeNode* node = q.front(); // Peek at front
q.pop(); // Dequeue from front (FIFO)
currentLevel.push_back(node->val);
// Enqueue children for next level
if (node->left) q.push(node->left);
if (node->right) q.push(node->right);
}
result.push_back(currentLevel);
}
return result;
}
Key: The level_size snapshot before the inner loop ensures we process exactly one level at a time, even as we add children to the queue.
BFS on Graphs
When extending BFS from trees to graphs, the critical addition is a visited set. Trees have no cycles, but graphs can, so without tracking visited nodes you risk infinite loops.
Python
from collections import deque
def bfs_graph(graph, start):
"""
BFS on an adjacency list graph.
graph: dict mapping node -> list of neighbors
start: the starting node
"""
visited = set() # Track visited nodes to avoid cycles
visited.add(start) # Mark start as visited BEFORE enqueueing
queue = deque([start]) # Initialize queue with start node
order = [] # Stores the BFS traversal order
while queue:
node = queue.popleft() # Dequeue from front
order.append(node) # Process current node
for neighbor in graph[node]: # Explore all neighbors
if neighbor not in visited: # Only visit unvisited nodes
visited.add(neighbor) # Mark visited BEFORE enqueueing
queue.append(neighbor) # Enqueue for later processing
return order
Java
import java.util.*;
public List<Integer> bfsGraph(Map<Integer, List<Integer>> graph, int start) {
List<Integer> order = new ArrayList<>();
Set<Integer> visited = new HashSet<>(); // Prevent revisiting nodes
Queue<Integer> queue = new LinkedList<>();
visited.add(start); // Mark start as visited
queue.offer(start); // Enqueue start node
while (!queue.isEmpty()) {
int node = queue.poll(); // Dequeue from front
order.add(node); // Process current node
// Explore all neighbors
for (int neighbor : graph.getOrDefault(node, Collections.emptyList())) {
if (!visited.contains(neighbor)) { // Only unvisited
visited.add(neighbor); // Mark visited first
queue.offer(neighbor); // Then enqueue
}
}
}
return order;
}
C++
#include <queue>
#include <unordered_set>
#include <unordered_map>
#include <vector>
vector<int> bfsGraph(unordered_map<int, vector<int>>& graph, int start) {
vector<int> order;
unordered_set<int> visited; // Track visited to prevent cycles
queue<int> q;
visited.insert(start); // Mark start as visited
q.push(start); // Enqueue start node
while (!q.empty()) {
int node = q.front(); // Peek front
q.pop(); // Dequeue
order.push_back(node); // Process node
// Explore all neighbors
for (int neighbor : graph[node]) {
if (visited.find(neighbor) == visited.end()) { // Unvisited?
visited.insert(neighbor); // Mark visited first
q.push(neighbor); // Then enqueue
}
}
}
return order;
}
Critical difference from tree BFS: always mark a node as visited when you enqueue it, not when you dequeue it. This prevents the same node from being added to the queue multiple times.
Common BFS Patterns
| Operation |
Time Complexity |
Space Complexity |
| Level order traversal |
O(n) |
O(n) |
| Shortest path (unweighted) |
O(V+E) |
O(V) |
| Connected components |
O(V+E) |
O(V) |
| Multi-source BFS |
O(V+E) |
O(V) |
Key insight: All BFS operations share the same time complexity because each node and edge is visited at most once. The space varies based on the maximum queue size at any point.
Professional Patterns
Sentinel / Marker Approach
Use None (Python) or null (Java/C++) as a marker in the queue to indicate level boundaries.
def bfs_sentinel(root):
"""BFS using None as a level boundary marker."""
if not root:
return []
result = []
current_level = []
queue = deque([root, None]) # None marks end of first level
while queue:
node = queue.popleft()
if node is None:
result.append(current_level)
current_level = []
if queue: # More levels to process?
queue.append(None) # Add marker for next level
else:
current_level.append(node.val)
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
return result
Level Size Approach (Preferred)
Track the queue size at the start of each level. This is the cleaner, more widely preferred approach in production code.
def bfs_level_size(root):
"""BFS using level size tracking — preferred approach."""
if not root:
return []
result = []
queue = deque([root])
while queue:
level_size = len(queue) # Snapshot: how many nodes at this level
current_level = []
for _ in range(level_size): # Process exactly one level
node = queue.popleft()
current_level.append(node.val)
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
result.append(current_level)
return result
This approach is preferred because it avoids polluting the queue with sentinel values and is easier to reason about.
Bidirectional BFS
For shortest path problems where you know both the start and end, search from both directions simultaneously. This reduces the search space from O(bd) to O(bd/2), where b is the branching factor and d is the depth.
def bidirectional_bfs(graph, start, end):
"""Find shortest path using BFS from both ends."""
if start == end:
return 0
# Two frontiers: one from start, one from end
front_visited = {start}
back_visited = {end}
front_queue = deque([start])
back_queue = deque([end])
depth = 0
while front_queue and back_queue:
depth += 1
# Expand the smaller frontier (optimization)
if len(front_queue) <= len(back_queue):
if _expand_level(graph, front_queue, front_visited, back_visited):
return depth
else:
if _expand_level(graph, back_queue, back_visited, front_visited):
return depth
return -1 # No path found
def _expand_level(graph, queue, visited, other_visited):
"""Expand one level of BFS. Returns True if frontiers meet."""
for _ in range(len(queue)):
node = queue.popleft()
for neighbor in graph[node]:
if neighbor in other_visited:
return True # Frontiers met — path found!
if neighbor not in visited:
visited.add(neighbor)
queue.append(neighbor)
return False
Common Pitfalls
- Not tracking visited nodes in graph BFS: Without a visited set, cycles in the graph cause infinite loops. Always mark nodes as visited when you enqueue them.
- Modifying collection while iterating: Never add or remove elements from the queue inside a for-each loop over it. Use the level-size approach to safely iterate.
- Off-by-one errors in level counting: Remember that the root is at level 0 (or 1, depending on convention). Be consistent and clarify the convention before coding.
- Using a stack instead of queue: This is the most subtle bug — swapping the data structure turns BFS into DFS! Always use FIFO (queue), not LIFO (stack).
Production Considerations
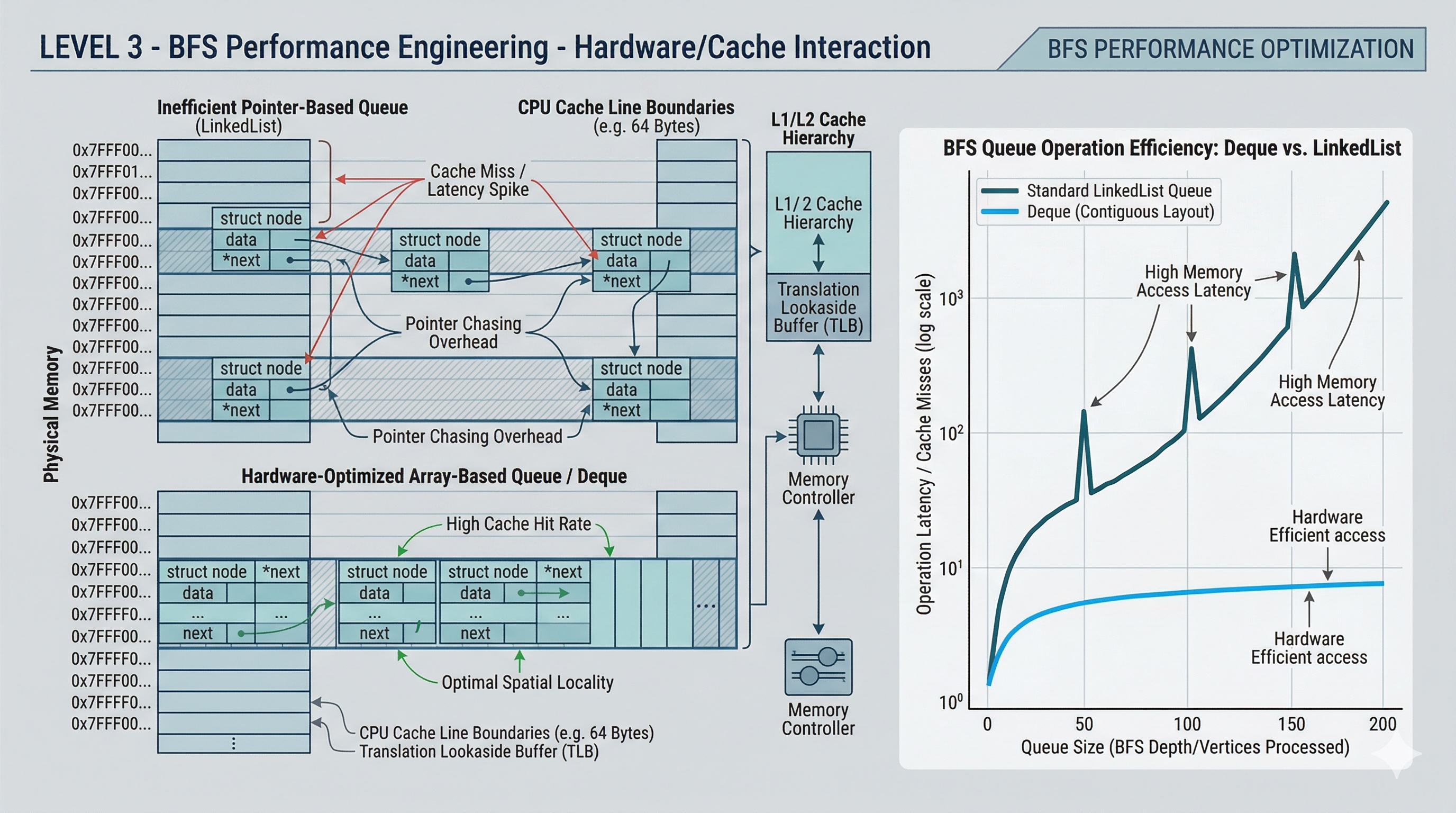
- Memory limits: BFS stores all nodes at the current level in the queue. For wide trees (e.g., a complete binary tree), the last level alone holds ~n/2 nodes, requiring O(n) memory.
- Iterative deepening DFS (IDDFS): In memory-constrained environments, consider IDDFS as an alternative. It achieves the same shortest-path guarantee as BFS but uses O(d) memory instead of O(n), at the cost of re-visiting nodes.
- Thread safety with shared queues: In concurrent systems, if multiple threads consume from the same BFS queue, use thread-safe queue implementations (e.g.,
ConcurrentLinkedQueue in Java) or synchronize access to prevent race conditions.
Key Takeaways
- The universal BFS template uses a queue (FIFO) and processes nodes level by level
- Tree BFS needs no visited set; graph BFS always needs one to prevent infinite loops
- The level size approach is the preferred professional pattern for level-aware BFS
- Bidirectional BFS dramatically reduces search space for shortest-path problems
- Mark nodes visited when enqueuing, not when dequeuing, to avoid duplicates in the queue