Understanding BFS: The Ripple Effect
Discover how Breadth-First Search works through a simple stone-in-a-pond analogy. Learn why BFS explores level by level and always finds the shortest path in unweighted graphs.
Discover how Breadth-First Search works through a simple stone-in-a-pond analogy. Learn why BFS explores level by level and always finds the shortest path in unweighted graphs.
Author
Mr. Oz
Date
Read
5 mins
Level 1
Author
Mr. Oz
Date
Read
5 mins
Share
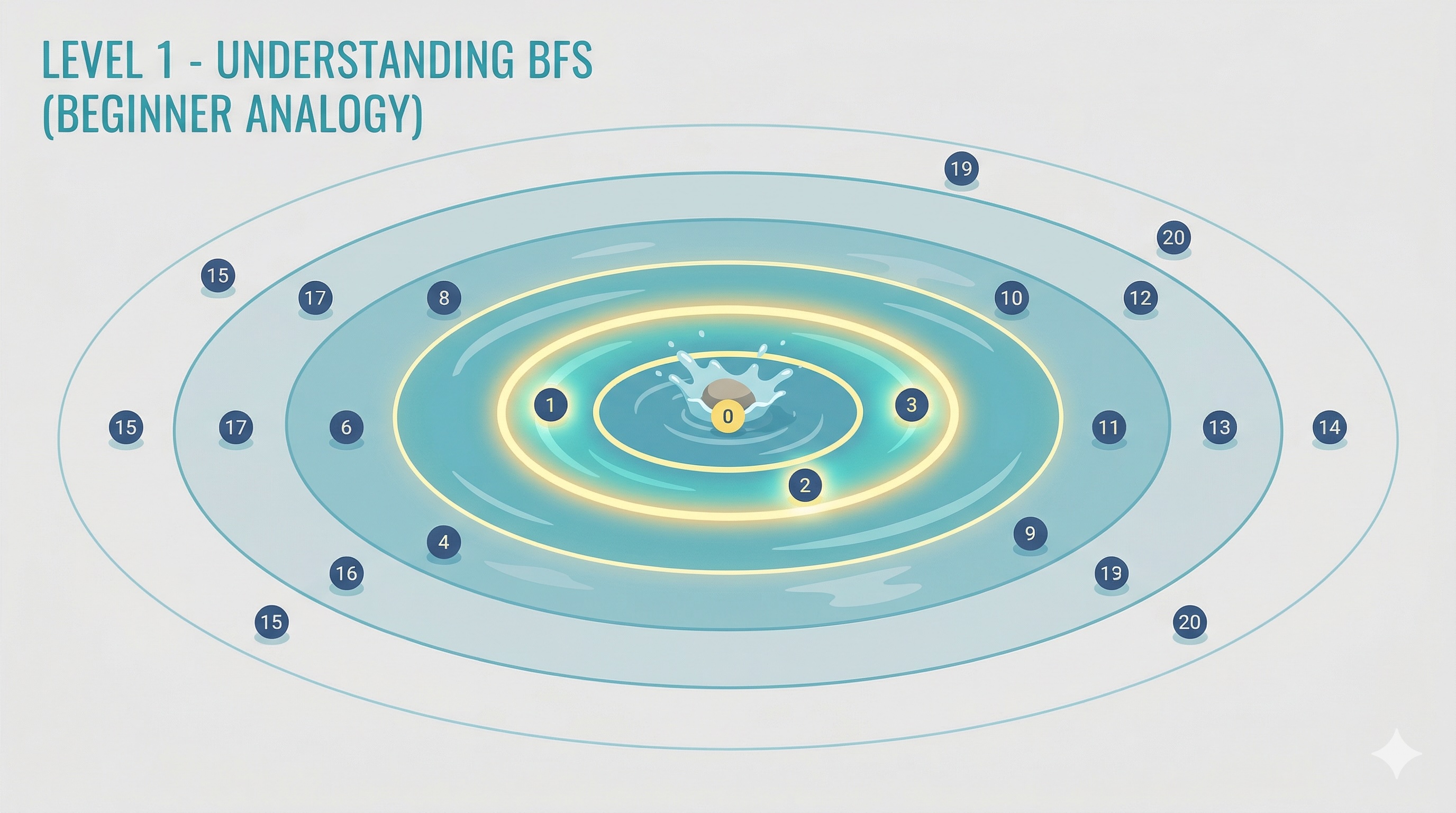
Imagine you drop a stone into a perfectly still pond. What happens? Ripples spread outward in circles — first the water closest to the stone moves, then the next ring, then the next. Each ring expands before the one after it begins.
This is exactly how Breadth-First Search (BFS) works. It explores all neighbors at the current distance before moving further out — layer by layer, ring by ring. Let's dive in.
Picture a calm pond. You pick up a stone and toss it into the center. The moment it hits the water, ripples begin spreading outward in concentric circles:
The stone never skips a ring. It never sends a ripple to the far shore before the nearby water has moved. The closest points are always reached first.
BFS Tip: BFS works exactly like these ripples. Starting from a node, it visits all immediate neighbors first (Ring 1), then their neighbors (Ring 2), and so on. No node at distance 3 is visited before all nodes at distance 2.
Let's switch to another analogy. Imagine you're a mail carrier in a small village. Your job is to deliver letters to every house, but you have a rule: deliver to all houses on your current street first, then move to the next street.
You keep a line (a queue) of houses to visit. The first house added to the line is the first one you deliver to. This ensures you complete each "level" before moving deeper.
A Level 0
/ | \
B C D Level 1
/| |
E F G Level 2
BFS visits: A → B, C, D → E, F, G
(All of Level 0, then Level 1, then Level 2)
BFS Tip: BFS always completes one entire level before moving to the next. This "level-by-level" behavior is what makes it so powerful for finding shortest paths.
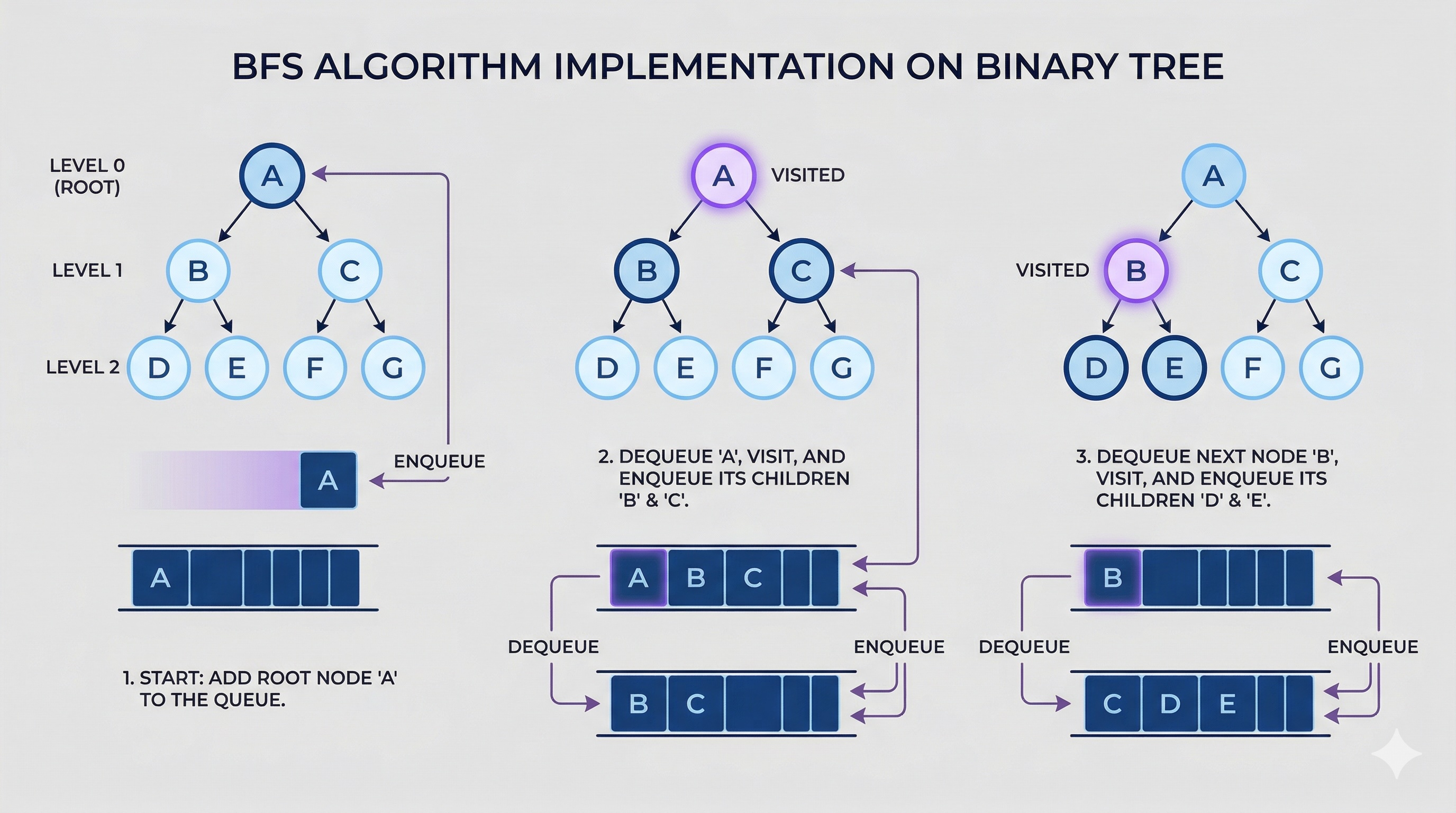
The secret behind BFS is a data structure called a queue. A queue follows the FIFO principle — First In, First Out.
Think of it like standing in line at a store. The first person who joins the line is the first person served. No cutting!
How the queue drives BFS:
Step 1: Start with A Queue: [A]
Step 2: Visit A, add neighbors Queue: [B, C, D]
Step 3: Visit B, add neighbors Queue: [C, D, E, F]
Step 4: Visit C (no new neighbors) Queue: [D, E, F]
Step 5: Visit D, add neighbors Queue: [E, F, G]
Step 6: Visit E Queue: [F, G]
Step 7: Visit F Queue: [G]
Step 8: Visit G Queue: [] Done!
Because the queue processes nodes in the order they were added, nodes discovered earlier (closer to the start) are always visited before nodes discovered later (further away). This is the engine that makes BFS work.
Because BFS explores nodes level by level, the first time it reaches any node is guaranteed to be via the shortest route. Here's why:
BFS Tip: This guarantee only applies to unweighted graphs (where every edge has the same cost). For weighted graphs, you'd need Dijkstra's algorithm instead.
Rule of thumb: Use BFS when you need the nearest or shortest. Use DFS when you need any path or when memory is limited — DFS only stores one path at a time, while BFS must store an entire level of nodes.
Ready for more?
Level 1
Learn how BFS works through a stone-in-a-pond analogy. Discover why it always finds the shortest path.
Author
Mr. Oz
Duration
5 mins
Level 2
Implementation details, queue usage, and production-ready BFS code examples.
Author
Mr. Oz
Duration
8 mins
Level 3
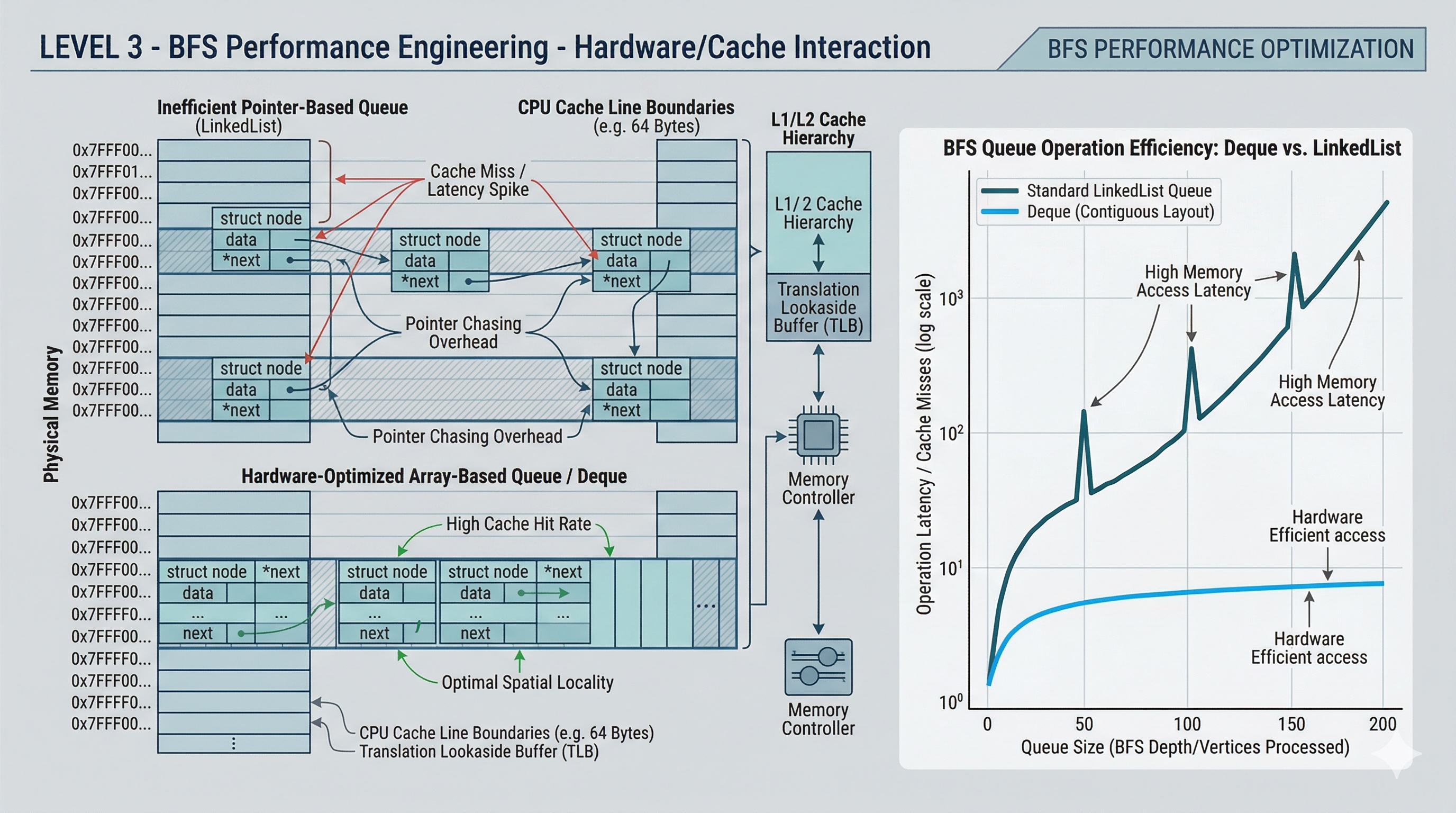
Memory optimization, bidirectional BFS, and advanced performance techniques.
Author
Mr. Oz
Duration
12 mins