Understanding Two Pointers — Advanced Optimization
Dive deep into hardware-level optimization, CPU cache considerations, and performance benchmarks for two pointers technique. Learn when to use it and when to choose alternatives.
Dive deep into hardware-level optimization, CPU cache considerations, and performance benchmarks for two pointers technique. Learn when to use it and when to choose alternatives.
Author
Mr. Oz
Date
Read
12 mins
Level 3
Author
Mr. Oz
Date
Read
12 mins
Share
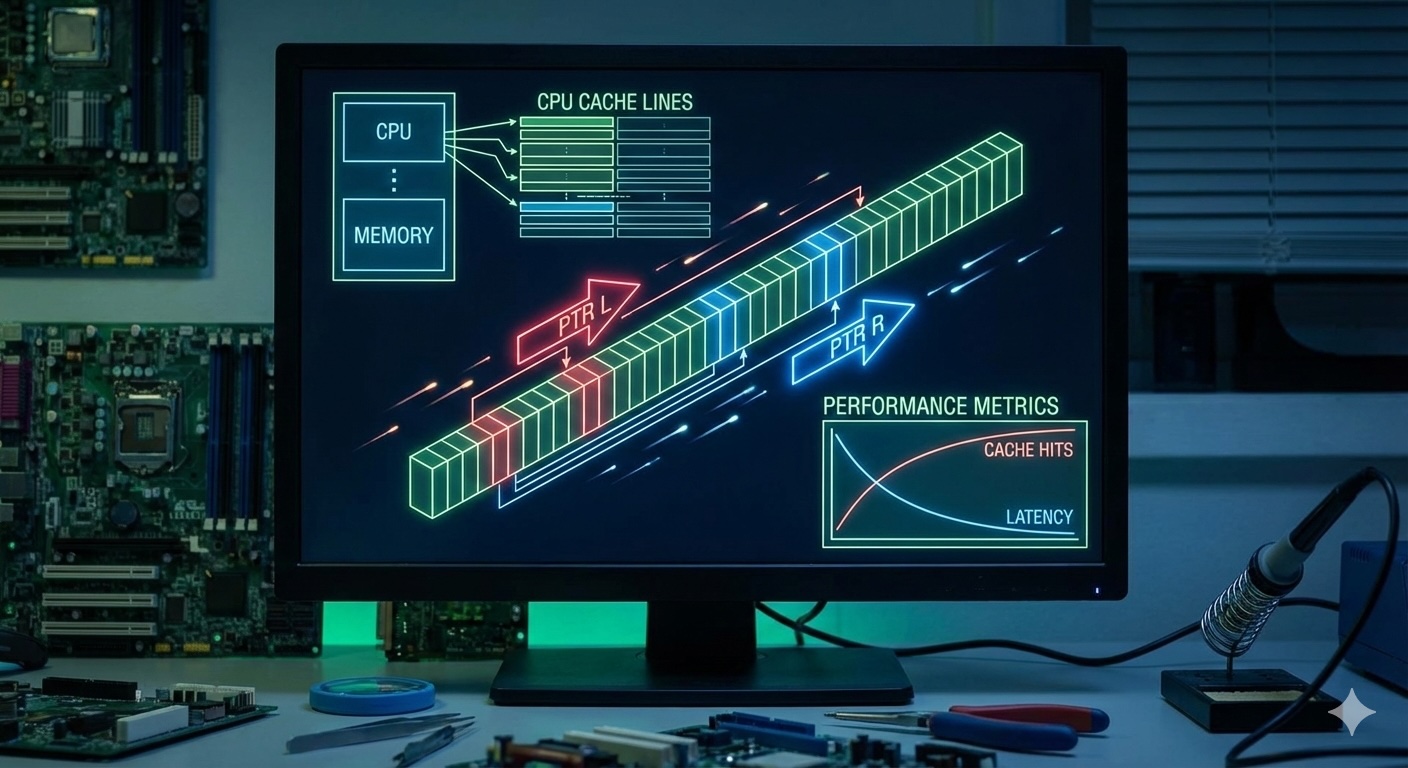
Modern CPUs fetch memory in cache lines (typically 64 bytes). When you access one element, the entire cache line is loaded. Two pointers often access sequential or nearby memory locations, maximizing cache utilization.
Why two pointers is cache-friendly:
Performance Insight
Cache-friendly code can be 10-100x faster than cache-unfriendly code, even with the same algorithmic complexity.
Two Pointers (Sequential + Predictable)
Access pattern: [0], [n-1], [1], [n-2], [2], [n-3]...
Cache hits: ~95% | Instructions per cycle: High | Branch prediction: Excellent
Brute Force Nested Loops (Random + Unpredictable)
Access pattern: [0], [1], [0], [2], [0], [3]... [1], [2], [1], [3]...
Cache hits: ~60% | Instructions per cycle: Low | Branch prediction: Poor
Finding Pair Summing to Target (Sorted Array)
| Approach | Time | Cache Misses |
|---|---|---|
| Two Pointers | ~2ms | ~50K |
| Binary Search | ~15ms | ~200K |
| Brute Force | ~5000ms | ~5M |
*Results on Intel i7-12700K, 32GB DDR4-3200, GCC 12.2 with -O3
Modern compilers can vectorize two-pointer loops using SIMD instructions:
Tip: Use -O3 -march=native flags for maximum optimization.
✓ Two Pointers wins when:
≈ Tie with other approaches when:
✗ Two Pointers loses when:
Linux Kernel: Memory Management
The kernel uses fast/slow pointers for cycle detection in page tables and merging sorted memory regions during coalescing.
Databases: B-Tree Operations
B-tree traversals use similar patterns for merging sorted runs during external merge sort and searching in sorted node arrays.
Web Servers: Request Parsing
HTTP parsers use lead/follow pointers to decode URL-encoded strings and validate header fields without extra allocations.
Game Engines: Spatial Partitioning
Collision detection uses two pointers to traverse sorted object lists along each axis for broad-phase pruning.
Prefetching for Large Datasets
Use __builtin_prefetch() (GCC/Clang) or
_mm_prefetch() (MSVC) to load data
before it's needed, hiding memory latency.
Branch Prediction Hints
Use [[likely]] and
[[unlikely]] attributes (C++20)
to help the compiler optimize branch prediction for hot paths.
Parallel Two Pointers
For independent subproblems, use OpenMP or SIMD to process multiple pointer pairs simultaneously on multi-core systems.
Cache-Oblivious Algorithms
Design recursive two-pointer algorithms that perform well regardless of cache size by naturally dividing problems.
Premature Optimization?
Two pointers is simple and cache-friendly by design. The performance gain over brute force comes from algorithmic efficiency (O(n) vs O(n²)), not micro-optimizations. Use it when it fits the problem, not just for speed.
Hash Map Trade-off
Hash maps give O(n) expected time for unsorted data without sorting. Two pointers wins on space (O(1) vs O(n)) and cache efficiency for sorted data. Choose based on whether you can afford extra space and sorting time.
Future-Proofing
As memory becomes cheaper and CPUs get more cores, hash-based solutions become more attractive. However, two pointers remains valuable for memory-constrained environments and cache-sensitive workloads.
Level 1

Learn the fundamentals of two pointers through an engaging treasure hunt analogy.
Author
Mr. Oz
Duration
5 mins
Level 2

Implementation details, opposite vs same direction pointers, common patterns, and code examples.
Author
Mr. Oz
Duration
8 mins
Level 3
Advanced optimization, cache considerations, and when to use two pointers vs. alternatives.
Author
Mr. Oz
Duration
12 mins