Understanding BFS vs DFS — Advanced Optimization
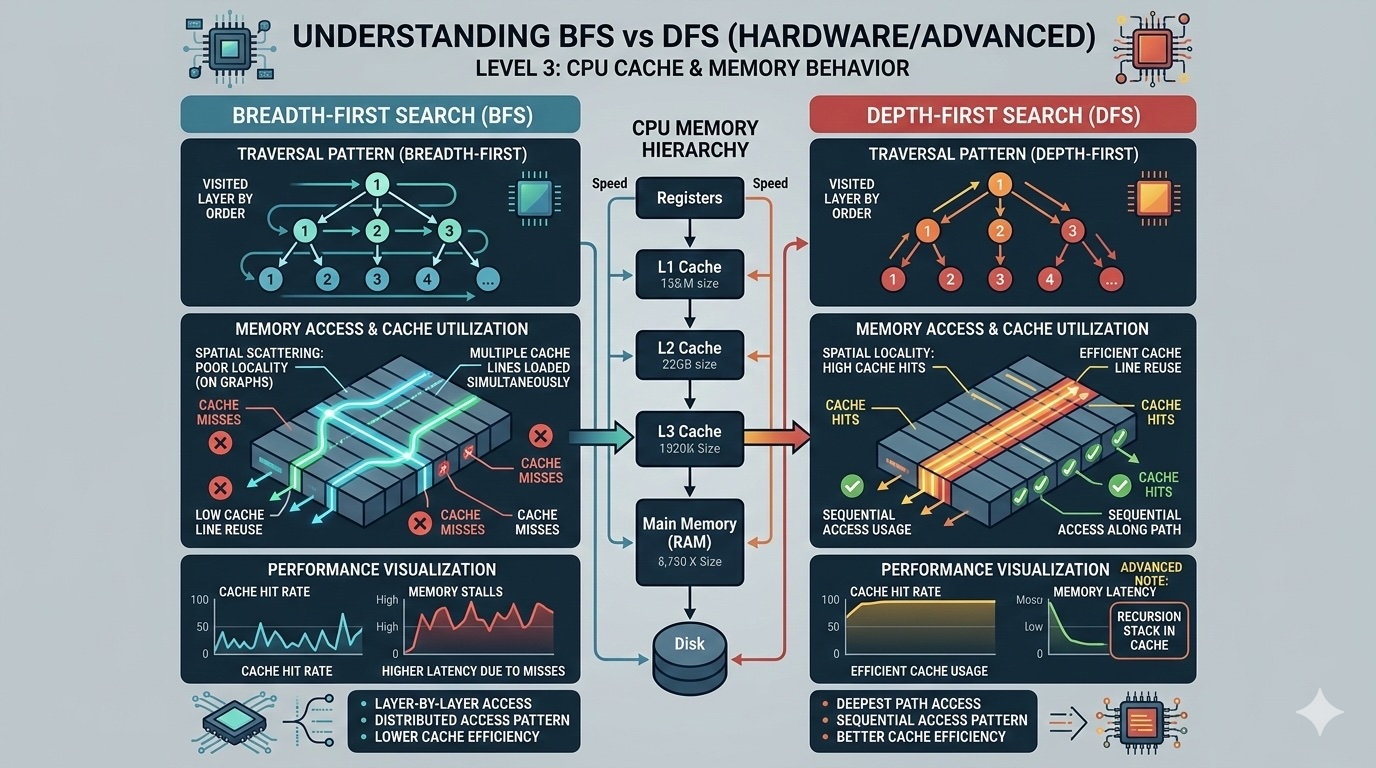
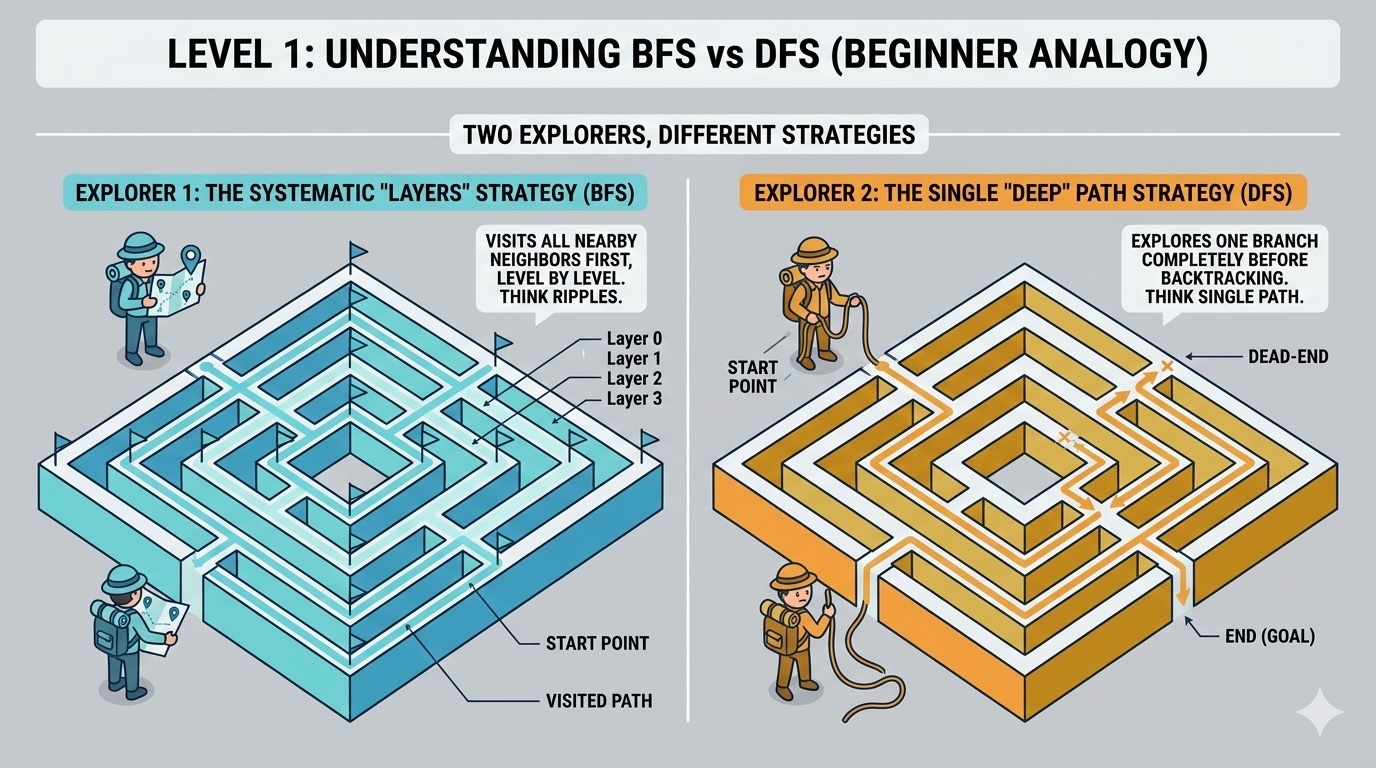
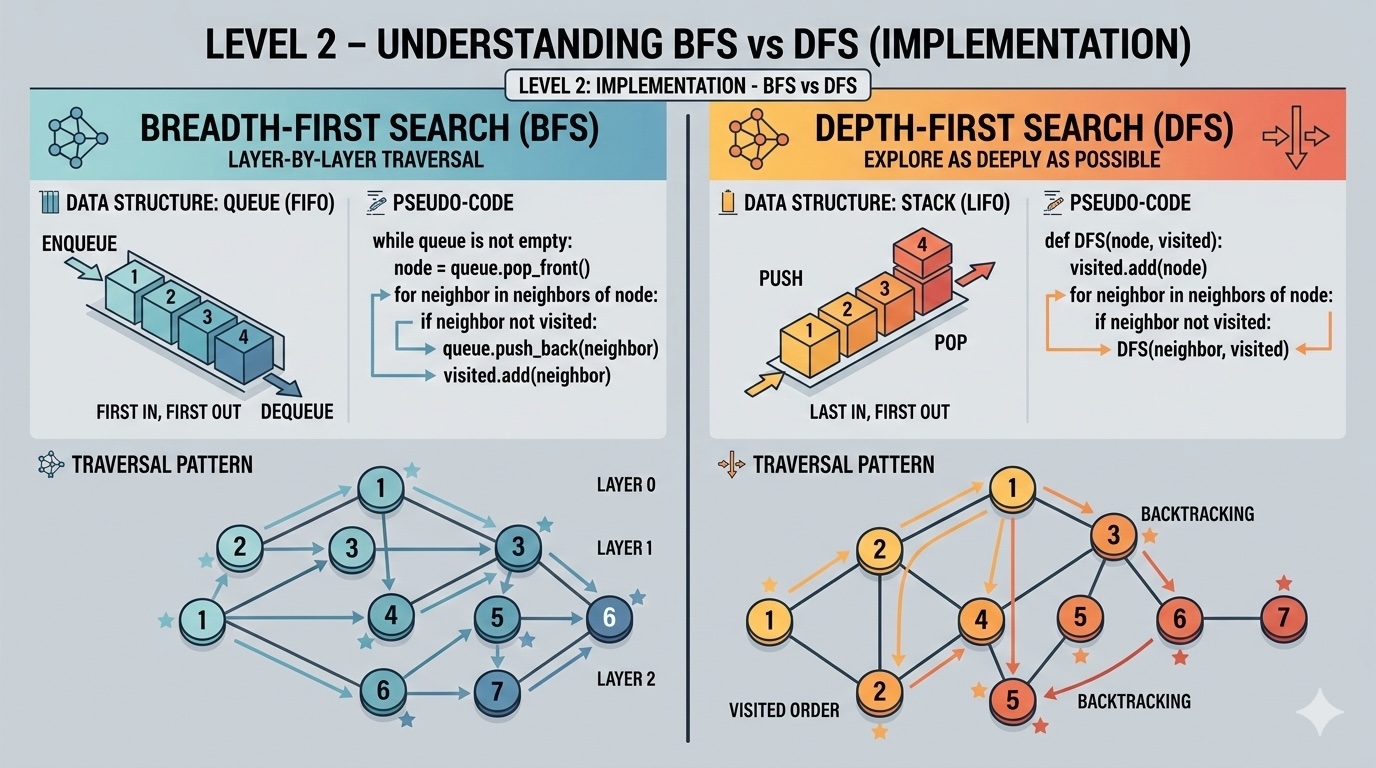
Explore the hardware-level implications of BFS and DFS. Learn how CPU cache, memory layout, and branch prediction affect real-world performance and discover optimization techniques used in production systems.