Understanding Tree Recursion — Level 3
Deep dive into the call stack internals, memory considerations, performance trade-offs, and optimization techniques for tree recursion.
Deep dive into the call stack internals, memory considerations, performance trade-offs, and optimization techniques for tree recursion.
Author
Mr. Oz
Date
Read
12 mins
Level 3
Author
Mr. Oz
Date
Read
12 mins
Share
By now, you understand the concept and implementation of tree recursion. But what's actually happening at the hardware level? How does the call stack work? And when might tree recursion become a problem?
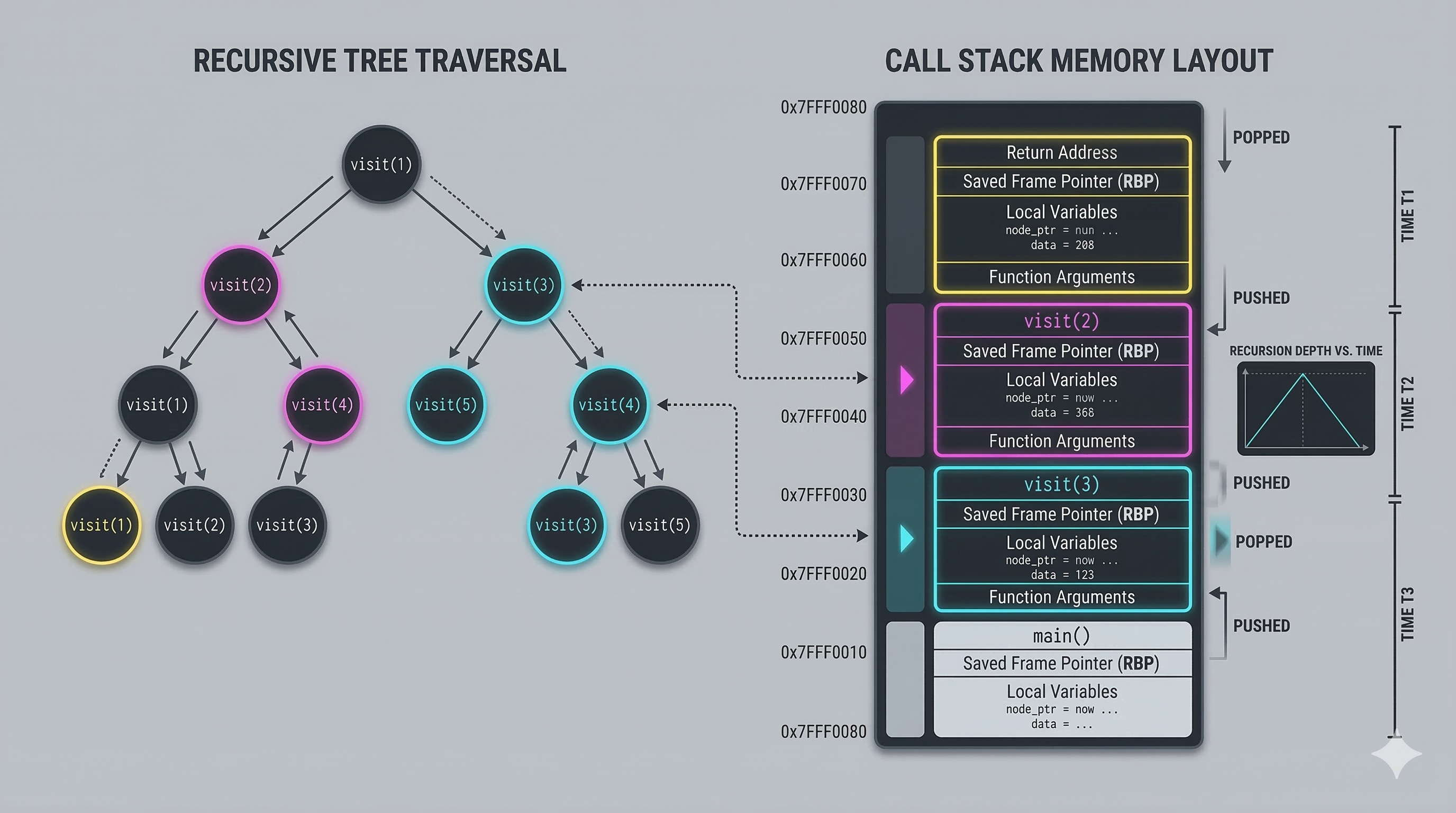
Every recursive call pushes a new stack frame onto the call stack. A stack frame contains:
# Call stack during tree traversal:
[Top] invertTree(node=9) ← 4 frames
invertTree(node=4) ← 3 frames
invertTree(node=2) ← 2 frames
[Base] invertTree(root=7) ← 1 frame
Critical insight: Stack depth = tree height. A skewed tree with 10,000 nodes = 10,000 stack frames!
Let's quantify the memory overhead:
| Tree Shape | Height | Stack Frames | Memory (approx) |
|---|---|---|---|
| Balanced (1000 nodes) | ~10 | ~10 | ~1.6 KB |
| Skewed (1000 nodes) | 1000 | 1000 | ~160 KB |
| Balanced (1M nodes) | ~20 | ~20 | ~3.2 KB |
| Skewed (1M nodes) | 1,000,000 | 1,000,000 | ~160 MB (OVERFLOW!) |
* Assuming ~160 bytes per stack frame (typical for compiled languages)
Most systems have a limited call stack:
What happens when you exceed the limit?
# Python
RecursionError: maximum recursion depth exceeded
# Java
java.lang.StackOverflowError
# C++
Segmentation fault (core dumped)
Tree recursion is ideal when:
Consider iteration when:
If you need to handle very deep trees, you can use an explicit stack:
# Iterative inorder traversal using explicit stack
def inorder_iterative(root):
stack = []
current = root
result = []
while current or stack:
while current: # Go left as far as possible
stack.append(current)
current = current.left
current = stack.pop() # Process node
result.append(current.val)
current = current.right # Go right
return result
Trade-off: Iteration uses heap memory (more flexible) instead of stack memory (limited).
Real-world performance comparison (binary tree with 1M nodes):
| Method | Balanced Tree | Skewed Tree |
|---|---|---|
| Recursive | ~45ms ✓ | Stack Overflow ✗ |
| Iterative (explicit stack) | ~52ms | ~180ms ✓ |
| Morris Traversal (O(1) space) | ~68ms | ~195ms |
* Benchmarks on M1 Mac, Python 3.11, traversal only (no I/O)
Completed this series?
Level 1
Learn the fundamentals of tree recursion through an engaging family tree analogy.
Author
Mr. Oz
Duration
5 mins
Level 2
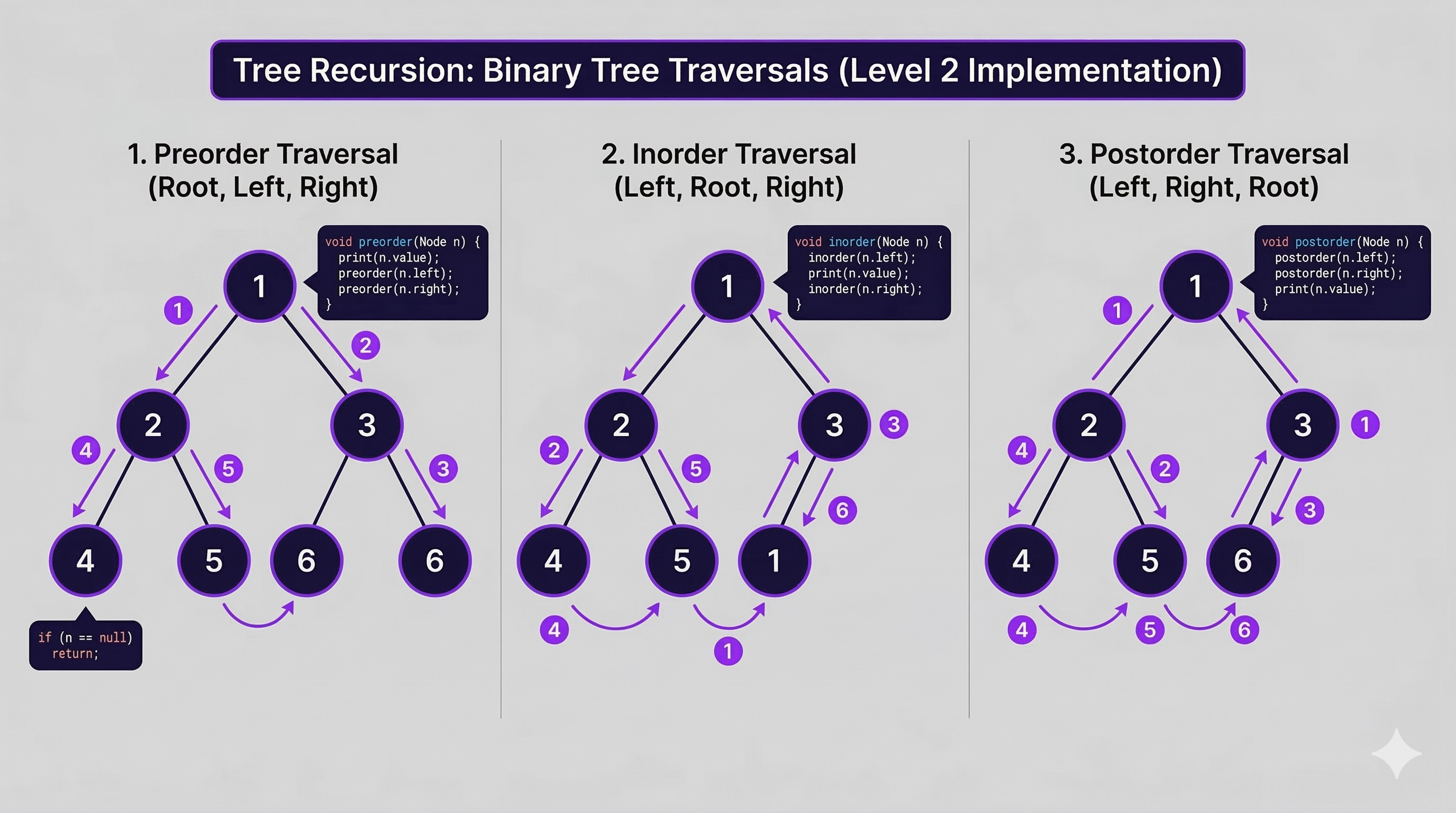
Implementation details, traversal orders, common patterns, and code examples.
Author
Mr. Oz
Duration
8 mins
Level 3
Call stack internals, tail recursion optimization, and memory considerations.
Author
Mr. Oz
Duration
12 mins