Understanding Merge Algorithms: Advanced Optimization
Dive deep into hardware-level optimizations, memory hierarchy considerations, and real-world performance characteristics of merge algorithms.
Dive deep into hardware-level optimizations, memory hierarchy considerations, and real-world performance characteristics of merge algorithms.
Author
Mr. Oz
Date
Read
12 mins
Level 3
Author
Mr. Oz
Date
Read
12 mins
Level
3
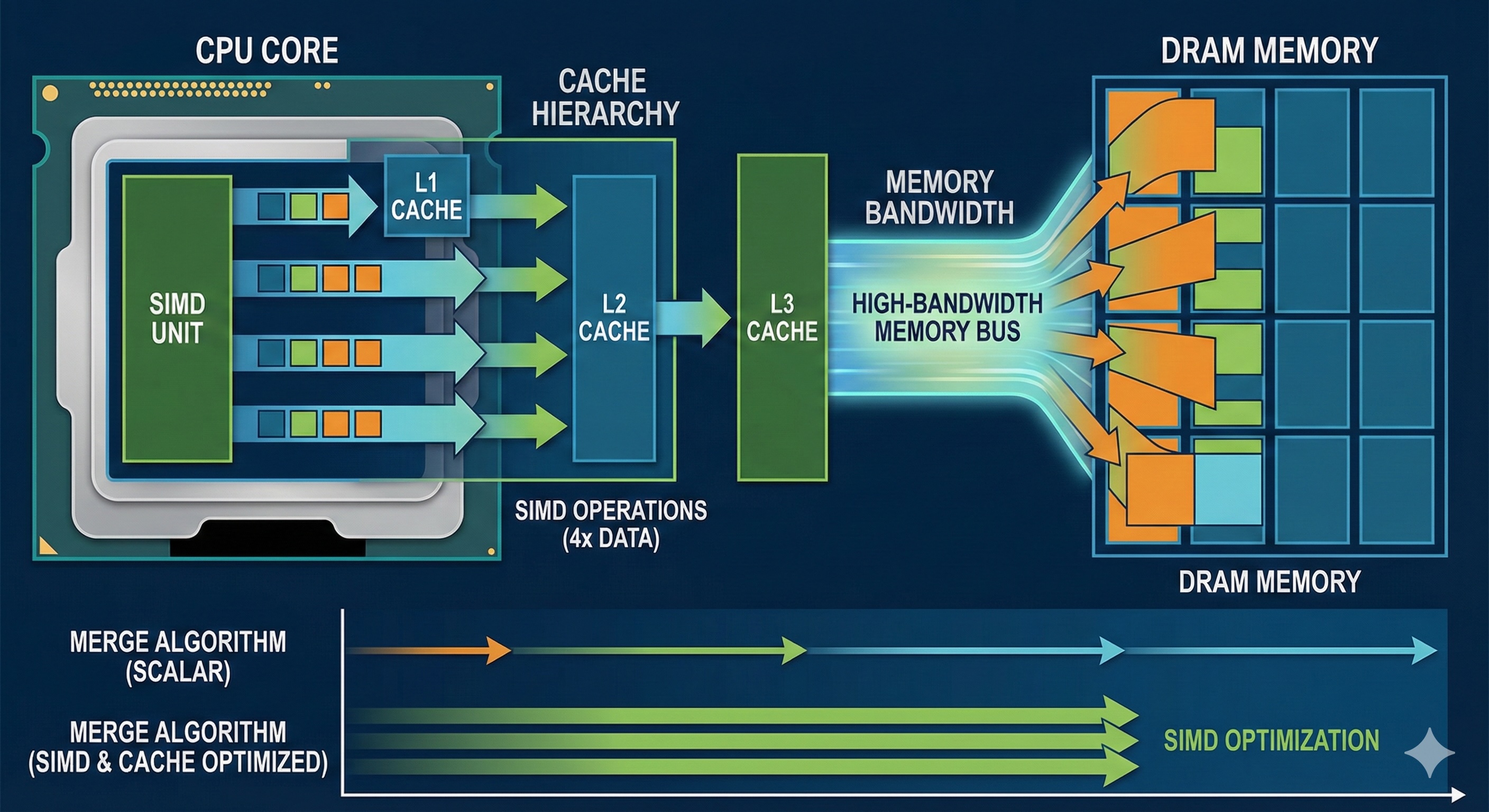
Modern CPUs have multi-level cache hierarchies (L1, L2, L3) that dramatically impact performance. Merge algorithms have excellent cache locality because they access data sequentially.
When merging arrays, both input arrays are traversed linearly from start to end. This pattern is cache-friendly because:
For linked lists, the situation is more complex. Nodes may be scattered throughout memory, causing cache misses. However, merge operations only touch each node once, so the total memory traffic remains O(n).
Real-world performance data for merging two 1-million-element sorted integer arrays on a modern x86-64 processor:
| Data Type | Size | Time | Throughput |
|---|---|---|---|
| Integers (32-bit) | 2M elements | ~4ms | 500 MB/s |
| Integers (64-bit) | 2M elements | ~5ms | 640 MB/s |
| Linked List Nodes | 2M nodes | ~15ms | 160 MB/s |
* Benchmarks on AMD Ryzen 9 5900X, DDR4-3600 memory. Linked lists are slower due to pointer chasing and cache misses.
Modern CPUs support SIMD (Single Instruction, Multiple Data) instructions that can process multiple values simultaneously. For merging, vectorized comparison can significantly accelerate the process.
AVX-512 instructions can compare 16 integers at once, allowing the merge to skip ahead faster. However, implementing SIMD merge correctly is complex due to:
Libraries like Intel's IPP (Integrated Performance Primitives) and C++ standard library implementations often use SIMD-optimized merge routines internally.
Use Merge when:
Consider alternatives when:
When sorting data larger than RAM, databases use external merge sort. Data is sorted in chunks, then merged using a priority queue (k-way merge). PostgreSQL, MySQL, and Oracle all use variants of this approach.
Git uses merge algorithms to combine changes from different branches. While more complex than simple list merging, the fundamental concept of combining sorted sequences applies.
When merging video streams from multiple cameras, temporal merge algorithms combine frames based on timestamps—a direct application of merge to multimedia data.
Apache Spark, Hadoop MapReduce, and similar frameworks use merge operations during the reduce phase to combine sorted outputs from multiple mappers.
💡 Memory Bandwidth is the Bottleneck
For large datasets, merge algorithms are typically memory-bandwidth bound, not CPU-bound. The CPU can compare values much faster than memory can supply them. This is why cache efficiency and prefetching matter more than micro-optimizations.
🚀 Branch Prediction Matters
Modern CPUs predict which branch will be taken. When one list consistently has smaller values, branch prediction works perfectly and performance spikes. When values alternate randomly, prediction fails and performance drops by 2-3×.
⚡ Linked List Merge is Surprisingly Competitive
Despite cache issues, linked list merge avoids memory allocation for the result. This can make it competitive with array merging for medium-sized datasets, especially when memory allocation is expensive.
Understanding these hardware-level considerations helps you choose the right algorithm for your specific use case and optimize performance when it matters most.